-
MBA
I would say it’s time for my annual update, but it’s like a year and a half now.
I actually started typing this from 40,000 feet above the Pacific Ocean, on my way to Maui last November, where the plan was to not think about technical writing, management, or work for seven days. I did okay with that, and feel free to bug me about my Maui restaurant list if you’re headed there. Thanks to Git, I started work on this while I was on the plane. That always seems to be the example they give in Git training, right? “So it’s all in your local repo. If you get on a plane and aren’t on the internet, you can still work.” Right? Well, I never pushed my commit, and I never finished writing, so maybe it’s not perfect.
The big update: I completed an MBA last year. This was at Western Governors University, which has a fully-remote, proficiency-based program. It’s a neat model for learning; basically, you enroll by the term, but then you finish classes as slow or as fast as you want. So instead of like enrolling in twelve credit hours for a semester, you do as many classes as you want to finish in six months.
I still worked full-time (or more than full-time, really), but I type fast. I was able to finish the two-year program in about five months. I started on June 1, and my graduation date was officially October 24, although I finished my last class about a week before that.
This program was an IT Management version of the MBA, so it contained a few courses specific to IT project management. But otherwise, it had all the same classes as a regular business MBA. (I think I skipped an operations management class, and a public speaking class, which was good. When I was an undergrad and had to take a speech class, I did it at 8 am in a summer session, so it was only six people.)
I think the first question people ask me is, “Why?” I know I don’t know any other tech writers with an MBA, and I have never applied for a job that required one. But I had a few thoughts about why I wanted to do this:
- I am a manager, and I never had any formal training as a manager. I have spent some time on Udemy watching leadership videos, and I have a whole shelf of half-read management books. But I felt like I needed something that said I was a manager, or at least something more than the few Agile crash course certification badges on my LinkedIn.
- I’ve always vaguely wanted a graduate degree, although never knew how that would happen.
- I don’t intend to move on to being a CTO or a PM or anything else. But I could see a future someday at some other company where another department got shoved next to the tech writing department (UX? research? QA?) and I would need to manage both. And I’d like to be prepared for that.
- I’m not starting a company. But in working at a start-up, I’m constantly inundated with discussion about financing and organization and whatever, so maybe I need to know more about it.
- This was way outside my wheelhouse. It would be hard. And I need to do things outside my wheelhouse that are hard.
- It’s arguably more interesting than doing crossword puzzles in my spare time to keep my brain from turning to goo.
The basic summary of the classwork is that things fell into three buckets:- Classes that were things I do every day without thinking, or have been trained on to the point of absurdity, and I just needed to get them done quickly. There were leadership, ethics, and people management classes in which more than 50% of the content was the mandatory training I have to take every year that says you shouldn’t bribe a foreign government.
- Classes that were interesting and fun. I took a marketing class where I had to write a marketing plan for releasing Taco Bell menu items in Japan. I also liked the IT classes, which involved things like doing a SWOT analysis for a company to pivot its IT infrastructure to the cloud.
- Classes that were climbing K2 without oxygen. I never took any business as an undergrad, and had to face three classes that almost ended me: accounting, finance, and econ. These were classes with math, equations, ratios, and lots and lots of raw memorization of hundreds of terms.
The capstone project, the big thing at the end, was a lot of fun. It basically put everything together and you had to run a business in a simulation for three quarters, competing against other people. A lot of people complained that the situation was insane, but it was honestly like playing Roller Coaster Tycoon for a grade. You had to run a bicycle company and decide on everything: factories, distribution, stores, bike features, R&D, marketing, everything. You had to pitch for venture cap after the first two quarters (which meant I did not avoid public speaking), and you had to write a shareholder report. It was fun making changes to see if I could increase output or sales.
Overall, the degree had five proctored tests and seven papers which totaled about 190 pages. There was some PowerPoint, and far too much Excel. Almost everything else was Word.
(Side note: I do not like Excel. Even worse than using it for legitimate purposes like accounting, I am really not into the standard use in tech writing, which is, “Let’s do a doc plan or analysis by pouring every filename into a sheet that is immediately obsolete and then putting a bunch of random checkmarks and notes and names in 17 columns, and then in a month, we will have no idea why we did this.” If you’re in that situation, use Jira. If you can’t use Jira, use Airtable. If you can’t use Airtable, you’re probably wasting your time on something that doesn’t matter and should stop.)
The last time I wrote an academic paper, I think I had to find things in a physical card catalog and then ask a librarian to pull the microfiche for me and pay ten cents a page to photocopy the article. Everything has changed 100%. OK, I use Word (begrudgingly) and get that part. But I’d never used a reference manager to track my citations, and that all magically works, without me remembering where the parenthesis go on an APA7 cite. The course was all e-books, and the papers I had to look up and cite were all online in their library. So, search “Jack Welch GE leadership traits” and find a result in Harvard Business Review, and there’s your PDF to skim. Find what you want, and there’s a link next to it with the cite. Copy and paste it exactly and you’re up against a plagiarism checker that will nail you for doing that. It was all completely different than when I would pay my girlfriend’s roommate to type my papers on a Brother word processor for me.
So, what did I learn? I don’t know how much of this applies directly to being a tech writing manager. But I think for a person living within the wheelhouse of big tech and seeing finance and business in the news, it’s invaluable. Just in general, I think it’s twisted my brain on how companies work. The second that Albertson’s/Kroger merger was announced, I pulled 10-K reports from the SEC for both parties, drilled down to the balance sheet, and started asking my better half (the consumer packaged goods expert of the family) dozens of questions, like “why does Kroger have almost two billion dollars of cash on hand during a pandemic?” From a practical perspective, I think I knew a lot of the IT management stuff like budgeting and SWOT analysis, but it was nice to do it on paper, and the next time I have to do a major tooling acquisition, I know how to make it look.
WGU was great, too. I love the model, and everyone I worked with was awesome. I talked my sister into going back for her Master’s degree in the education school. And spoiler alert, I’m actually halfway done with another degree. More on that later.
-
Liquid code blocks in Jekyll posts
This came up in the factorials post I did recently, and it was a bit maddening, so here’s a quick reference, so I remember it two years from now when it comes up again.
Typical fenced code blocks in Jekyll (and any other Markdown situation) are surrounded with lines that are nothing but a triple backslash. (Your Markdown processor might also define a code language on the first line, so throwing a
jsonon there might give you pretty formatting or color-coding, depending on your tools.) Example:{ "book": { "title": "Infinite Jest", "author": "David Foster Wallace" } }Here’s what that looks like in my editor:

Now let’s say you need to add an example of some code using the Liquid template language, as one might need to do when talking about Jekyll themes. When you get into your first full block of code with things like surrounding
page.titlewith two curly brackets on either side of it, Jekyll’s going to start evaluating the code, even if it’s inside a block or a piece of inline code (hence me describingpage.titlewith two curly brackets on either side of it instead of showing it). Liquid code takes precedence over any Markdown escaping.Liquid has a set of tags named
rawandendrawto solve this. You can use these to surround a code block containing Liquid. The nesting is really touchy though, and there’s a good chance your editor’s preview won’t show it right.Two quick examples: First, you can put an inline example on a line. The output looks like this:
{% assign n = 20 %}.Output of a fenced code block looks like this:
{% assign result = 1 %} {{ result }}Here’s what these look like in my editor:

Your mileage may vary; like I said, this is touchy. Make sure to fire up Jekyll locally and test it. Bad combinations will show up as errors in your server output.
-
GitHub Pages Custom Domains
I moved this site from Wordpress to GitHub pages a few months ago, and when I got to redirecting the domain, I punted and put an
.htaccessfile on the old site and 301’ed it over. That almost worked, but after each redirect happened, any old URLs were sent tojkonrath.github.io/, which broke all of my old links. I needed to properly point my hostname to the right place, and this was a bit maddening.Here’s what I did to get it to work. My domain is registered at Pair Domains, and my old site was running at Pair. This assumes you have created a GitHub account and a repo for your GitHub pages stuff, and have an address like I have
jkonrath.github.io.Disclaimer: I’m not an IT professional, and you could mess up everything by listening to me. You probably shouldn’t listen to me about anything, let alone something involving data loss. You’ve been warned.
The Pair part:
- Log in to the Pair ACC site. Back up the old WordPress site. Don’t forget to back up the database, too.
- Go to Domains and select the domain from the list.
- Select Delete Domain From Account.
I only needed to do these three things because the domain was pointed at an IP and subdirectory of another host I run there. If you only registered a domain at Pair Domains and don’t host the site there, you don’t have to do this.
- Log in to the Pair Domains site, and select your domain name.
- Go to Domain Address Settings. This may be disabled by default; I had to accept terms and turn it on first.
- If you have Website Forwarding set, turn that off by deleting the forwarding URLs.
-
From the Add New Record dropdown list, select CNAME (Parking).
- In the left side under Alias, put
www. - In the right, under Points To, put
yourusername.github.io. - Select Add Record.
- In the left side under Alias, put
- Go back to Add New Record, and select A (Round Robin).
- Under Host Name, put
@and under IP Addresses, put these four IP numbers:185.199.108.153 185.199.109.153 185.199.110.153 185.199.111.153 - Select Add Record. You will now have a CNAME for www pointing to your GitHub Pages domain, and four A records pointing to the IP addresses above.
Note: Double-check this nine times. The CNAME is
www >> yourusername.github.ioand there are four A records that are@ >> 185.199.x.yIf you get thewwwand@backwards, this won’t work.After you do this, you have to wait. It could be a minute; it could be a day. A good way to test it is whatsmydns.net, which shows how your changes have propagated around the world.
Once that sorts itself out:
- Go to GitHub, and open the repo for your blog.
- Select Settings, then Pages. It will say your page is being hosted at
yourusername.github.io. If it isn’t, you’ve got bigger problems. Sort those out first. - Under Custom Domain, enter the custom domain and select Save. You’re putting in
www.my-host-name.com. There’s no protocol in front of it (http://) but don’t forget the www. - This will churn away and check the DNS for you. It will also kick off a request to Let’s Encrypt to make a certificate for free. You do not have to pay for anything at Pair or do any other legwork to get this done. The catch is that if you messed up the first part, or if GitHub’s feeling grumpy, that creation step will get botched, and you won’t get any helpful information, except it won’t work.
- Leave it alone for an hour or a day, and then you can select Enforce HTTPS and it will (eventually) enable HTTPS.
On the last step: it may give you a byzantine error message, like “Unavailable for your site because a certificate has not yet been issued for your domain.” If that happens:
- Make sure your CNAME and A records on Pair Domains are correct.
- Wait a bit.
- Under Custom Domain in the GitHub Pages config, select Remove, then add it again. This will redo the request for a new certificate. Or not. I think I did it five times before it took.
You may need to clear your browser cache or wait a bit more until this works, but test it with and without HTTPS and www.
-
Interview question - calculating a factorial
When I was a tech writer, almost every time a developer interviewed me, they would inevitably ask me to whiteboard how to calculate the factorial of a number. When I moved to Northern California in 2008 and started interviewing at various Bay Area tech firms, I was seriously asked to do this exact problem at least twelve times in interviews with three companies.
I thought of this recently after reading this, and thinking of the smart-aleck answers I never did give during interviews, like writing it in PostScript or COBOL.
(BTW, a factorial is the product of all positive integers between 1 and n. It’s denoted as n! So 4! = 1 * 2 * 3 * 4 = 24.)
Iteratively
The simple/obvious answer is doing it iteratively. In C:
int factorial(int n) { int i; int result=1; for (i=1; i<=n; i++){ result = result * i; } return result; }Extra credit:
- That should fail if you called it with a zero or a negative number.
- There isn’t a
main()that asks for a number and prints the result in a pretty way. - If you want to be cute, use the assignment operator
result *= iinstead ofresult = result * iand save nine keystrokes.
Recursively
They won’t always expect this from a writer who doesn’t regularly code, but here’s the other way to do it:
int factorial(int n) { if (n == 0) return 1; return n * factorial(n - 1); }You can make this way more incomprehensible with the ternary operator:
int factorial(int n) { return(n==1||n==0) ? 1 : n*(factorial(n-1)); }…Other
Scheme
I went to Indiana University at a time when the first three or four computer science classes were all taught in Scheme. I always wanted to whiteboard this as an answer:
(define (factorial n) (cond ((equal? n 0) 1) (else (* n (factorial (- n 1))))))Extra credit: do it with tail recursion.
Liquid
This blog is in Jekyll, so maybe you’ve worked with Liquid templates before:
{% assign n = 20 %} {% assign result = 1 %} {% for i in (1..n) %} {% assign result = result | times i %} {% endfor %} {{ result }}(Tip: if you have to put a Liquid template in a code block in Jekyll, look at the source of this page in GitHub. I’d explain, but delimiting the text in another example isn’t working.)
REST API
APIs are the future (not speaking for my employer, of course) so maybe you want to use a REST API to do it:
curl http://api.mathjs.org/v4/?expr=5!(Why use cURL though? There’s a much better way.)
Standard libraries
If they forget to qualify their question with “don’t use standard libraries” you can do this (Python):
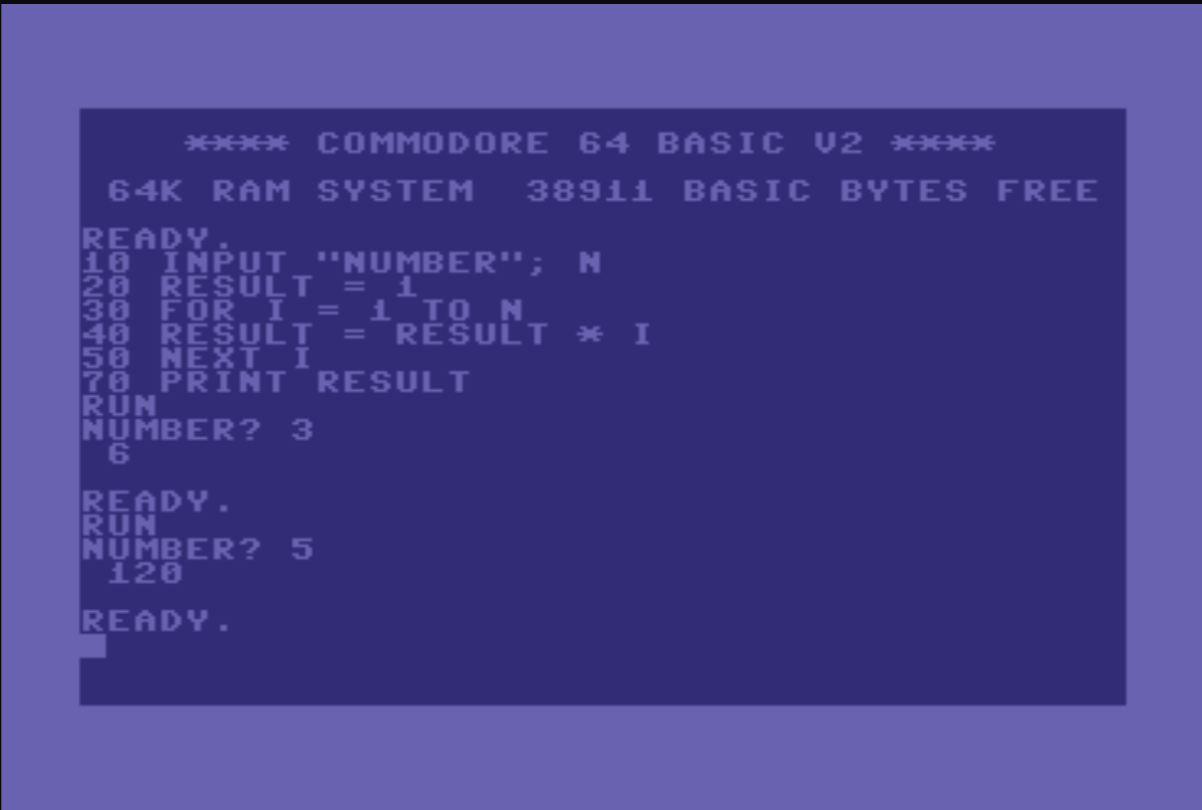
import math def factorial(x): print (math.factorial(x))Commodore BASIC 2.0
Let’s take it back to the beginning:
SQL
I was trying to figure this out, but my SQL days are long behind me. You could use a recursive common table expression to create a table of n rows with each row containing the result of the previous row multiplied by the row number… or something.
PDF
This is the point in my research where I had to give up and walk away for a bit. But if you had the right PDF CLI library, you could write a shell script that creates a one-page blank PDF, then iteratively merges copies of that template PDF onto a result PDF and count the number of pages at completion. There’s some magic number limit of objects in the PDF specification so they still work on 32-bit machines – eight million or so – which means this would break just past the factorial of 10.
Actually, a lot of these would break after about 12, when you’d hit
INT_MAX. There’s a way to do bigger numbers by creating an array of the number of digits you want to calculate, then writing a multiply function that does all of the carrying when each spot in the array goes past 9, etc. If you really want to push it, use a linked list instead of an array so you won’t waste any space. This probably won’t fit on one whiteboard.PostScript
Oh, here it is in PostScript (I don’t know PostScript anymore; I borrowed it from here…)
/factorial { 1 dict begin /n exch def n 0 eq { 1 }{ n n 1 sub factorial mul } ifelse end } def(The serious answer to all of this, if you’re a developer tasked with interviewing a tech writer, is to ask them about their problem-solving methodology, and how they figure things out when they don’t know the answer. People who have to write a code sample every other month won’t know off the top of their head how to reverse a linked list. They should be able to talk you through a difficult problem they had to solve once, though. It’s probably a cross-functional review, right? Test their soft skills, not their ability to memorize. Just my opinion.)
-
Atom as a Markdown Editor
(Update: nope. I’ve since switched to VSC, so looks like you should too. I’ll leave this here for nostalgia purposes.)
Part of this switch to Jekyll I mentioned previously is that I now edit this site in Markdown instead of WordPress. The great thing about Markdown is you can theoretically edit it in anything; you could even use Notepad or TextEdit or even the DOS Edlin editor to make a Markdown file. But you probably want something that adds some conveniences, like a few key bindings to save some time typing, a preview pane, and the ability to search and replace multiple files.
When I first started using Markdown at work in 2015, I looked for a good editor that would do all of this, but never entirely found it. I stumbled through trying to set up Notepad++ like an IDE (I was stuck on a Windows machine), and I almost considered setting up Eclipse as a Markdown editor, but then I remembered it wasn’t 2003.
I eventually settled on using Atom, which is a text editor-slash-IDE released by GitHub. It’s free, open-source, and customizable, with a lot of optional packages that are easy to add.
Here’s what I did to set up Atom for my Markdown editing needs:
-
Not part of Atom per se, but life is much easier when I’m also using GitHub Desktop along with it. It makes it much easier to handle git commits/pushes/merges/branches. Atom does have its own git integration down in the lower right corner, where you see your current branch, do a quick fetch, and see PR review comments.
-
First thing I do is change the theme, because I can’t deal with dark mode (sorry). Go to Preferences > Settings > Themes and pick something; I usually go with One Light, but there are many options.
-
Then go to Preferences > Settings > Install and grab the following:
language-markdown- adds grammar support for MD files.markdown-writer- adds more MD writing features.markdown-preview-enhanced- there are a few previewers out there, but this one seems to work best for me. I had problems withmarkdown-previewhandling Jekyll files; maybe that’s fixed now?
-
Go to Preferences > Settings > Packages and go to the settings for the
spell-checkpackage. In the Grammars section, addtext.md. -
If you File > Open to the directory of your project, it opens it with the hierarchy shown in the left sidebar, and you can then click around in that to open various files.
I’ve been using this setup daily for a while now at work. But now everyone’s using Visual Studio Code, so maybe I need to switch.
-